Bạn đang quan tâm đến Bài 3. Phân tích hồi quy tuyến tính bội (Multiple Linear Regression) phải không? Nào hãy cùng PHE BINH VAN HOC theo dõi bài viết này ngay sau đây nhé!
Video đầy đủ Bài 3. Phân tích hồi quy tuyến tính bội (Multiple Linear Regression)
1. khi nào sử dụng?
hồi quy nhiều tuyến tính là một phần mở rộng của hồi quy tuyến tính đơn giản. được sử dụng khi chúng ta muốn dự đoán giá trị của một biến phản hồi dựa trên giá trị của hai hoặc nhiều biến hồi quy. biến mà chúng ta muốn dự đoán được gọi là biến đáp ứng (hoặc đôi khi là biến phụ thuộc). các biến mà chúng ta sử dụng để dự đoán giá trị của biến phản ứng được gọi là biến giải thích (hoặc đôi khi là biến dự báo, biến phụ thuộc). ví dụ: chúng tôi có thể sử dụng hồi quy bội để biết liệu có thể dự đoán kết quả bài kiểm tra toán diễn giải dựa trên thời gian ôn tập và giới tính của học sinh hay không.
Hồi quy bội cũng cho phép chúng tôi xác định mức độ phù hợp tổng thể của mô hình và đóng góp tương đối của mỗi yếu tố dự đoán vào tổng phương sai được giải thích. ví dụ: chúng tôi có thể muốn biết có bao nhiêu phương sai trong kết quả kỳ thi cuối kỳ môn toán giải thích có thể được giải thích bằng thời gian xem xét và giới tính “tổng thể”, cũng như “đóng góp tương đối” của mỗi biến độc lập để giải quyết phương sai.
2. giả thuyết vô hiệu và suy luận thống kê
Khi có nhiều hơn một biến độc lập, mức độ phù hợp tổng thể của mô hình được đánh giá bằng cách sử dụng thống kê f (thống kê f). giả thuyết rỗng được kiểm tra đối với tất cả các tham số hồi quy ngoại trừ điểm chặn. Ví dụ: nếu có ba biến giải thích trong mô hình, giả thuyết rỗng sẽ là: h0: β1 = β2 = β3 = 0 . thống kê f được đánh giá là tỷ lệ giữa bình phương trung bình của mô hình với bình phương trung bình của lỗi .
3. giả định thống kê
Khi phân tích dữ liệu bằng cách sử dụng hồi quy tuyến tính, một phần của quy trình bao gồm việc kiểm tra để đảm bảo rằng dữ liệu bạn muốn phân tích thực sự có thể được phân tích bằng cách sử dụng hồi quy tuyến tính. tập dữ liệu phải “vượt qua” các giả định cần thiết để hồi quy tuyến tính đưa ra kết quả hợp lệ.
- phép đo của biến phản hồi y ít nhất phải liên tục về mặt lý thuyết. (ví dụ: có thể sử dụng điểm thang đánh giá; 0, 1, 2, 3… n) và trong nhiều hồi quy, một hoặc nhiều biến giải thích có thể là nhị phân (ví dụ: trong hồi quy, chúng được gọi là biến giả , biến nhị phân giới tính có thể được mã hóa là 0 = nam, 1 = nữ) hoặc biến thứ tự.
- mối quan hệ giữa phản hồi và các biến giải thích phải gần như tuyến tính. được xác minh bằng cách vẽ biểu đồ biến phản hồi so với từng biến độc lập trong mô hình. mối tương quan chặt chẽ được chỉ ra bởi xu hướng đường thẳng rõ ràng trong sự lan truyền của các điểm.
- error ( error ) trong mô hình hồi quy, ε , phải có phân phối xác suất chuẩn . phần còn lại trong phân tích hồi quy đại diện cho các ước tính mẫu về lỗi . chúng phải có giá trị trung bình bằng 0 và phương sai không đổi (điều này được gọi là tính đồng nhất – phương sai thay đổi ). Lưu ý rằng không phải phản hồi và hồi quy phải được phân phối bình thường , các phần dư tương ứng là bình thường.
– kiểm tra giả định về tính chuẩn bằng cách lập đồ thị xác suất bình thường của các phần dư. phân bố phần dư chỉ cung cấp một dấu hiệu về sự phân bố sai số cơ bản trong tổng thể và có thể không đáng tin cậy với các cỡ mẫu nhỏ. diễn giải biểu đồ xác suất chuẩn theo cách giống như được mô tả trong ‘thử nghiệm phân phối chuẩn’.
– kiểm tra giả định phương sai không đổi (hoặc kiểm tra tính đồng nhất) bằng cách vẽ biểu đồ phần dư so với các giá trị dự đoán. sự chênh lệch ngẫu nhiên của điểm số đến giá trị trung bình bằng 0 cho thấy phương sai không đổi và thỏa mãn giả định này. nghĩa là, các biến thể dọc theo dòng phù hợp nhất vẫn tương tự khi bạn di chuyển dọc theo dòng. một mô hình kênh hiển thị phương sai không cố định. Có thể dễ dàng phát hiện những quan sát bên ngoài kỳ lạ trên biểu đồ này.
- phải không có ngoại lệ đáng kể . giá trị ngoại lai là một điểm dữ liệu quan sát làm cho giá trị của biến phụ thuộc rất khác với giá trị được dự đoán bởi phương trình hồi quy. đối với các giá trị ngoại lai (hoặc ngoại lệ), hãy xem kiểm tra ngoại lệ.
- dữ liệu không được hiển thị đa cộng tuyến, xảy ra khi hai hoặc nhiều biến độc lập có tương quan cao. điều này dẫn đến các vấn đề trong việc hiểu biến độc lập nào góp phần vào phương sai được giải thích trong biến phụ thuộc, cũng như các vấn đề kỹ thuật khi tính toán mô hình hồi quy nhiều lần.
Tất cả các giả định đều quan trọng, nhưng một số giả định quan trọng hơn những giả định khác. kinh nghiệm cho phép nhà nghiên cứu đánh giá mức độ các giả định có thể được nới lỏng trước khi các suy luận bị vô hiệu; đây vừa là một nghệ thuật vừa là một khoa học. ví dụ, độ không chuẩn của các phần dư không quan trọng, nhưng sai số chuẩn có thể bị phóng đại. Tương tự, việc thiếu phương sai không đổi không có khả năng làm sai lệch nghiêm trọng các hệ số hồi quy, nhưng các giá trị p liên quan nên được diễn giải một cách thận trọng. vi phạm nghiêm trọng nhất là sai lệch đáng kể so với tuyến tính. trong tình huống này, việc chuyển đổi dữ liệu hoặc một phương pháp phân tích thay thế nên được xem xét.
4. phân tích hồi quy nhiều tuyến tính trong spss
Ví dụ: chúng tôi có thể sử dụng hồi quy tuyến tính để hiểu liệu có thể dự đoán kết quả kỳ thi viết cuối cùng của học sinh dựa trên thời gian ôn tập cuối cùng dành cho việc học giải tích và điểm yếu hay không. yếu tố giới tính hay không. 20 học sinh được mời tham gia một thí nghiệm, trong đó, từ bài giải tích cuối cùng cho đến ngày thi cuối cùng, các em được yêu cầu ghi lại tổng số giờ ôn tập (cộng dồn cho mỗi ngày) dành cho môn toán. Vào cuối bài kiểm tra, nhà nghiên cứu đã thu thập điểm của 20 sinh viên này trên thang điểm 100, gán giá trị 1 = nữ, 2 = nam và tổng hợp chúng theo bảng sau.

Các bước bên dưới chỉ cho chúng tôi cách thực hiện phân tích hồi quy tuyến tính nhiều lần trên thống kê spss.
– bước 1: nhấp vào phân tích & gt; hồi quy & gt; tuyến tính…

– bước 2: trong hộp thoại hồi quy tuyến tính , chúng tôi thay đổi các biến giải thích ‘ thời gian xem xét ‘ và ‘ giới tính’ trong (các) bảng độc lập: , chuyển biến phản hồi ‘ diemthi ‘ vào (các) bảng phụ thuộc: ,

– bước 3: Bây giờ chúng ta cần kiểm tra các giả định, bao gồm: không có các giá trị ngoại lệ quan trọng (ngoại lệ), tính độc lập của các quan sát, tính đồng nhất, đa cộng tuyến và phân phối chuẩn sai số / thặng dư. chúng ta có thể làm điều này bằng cách sử dụng các hàm thống kê ( thống kê ) và biểu đồ ( đồ thị ), sau đó chọn các tùy chọn thích hợp trong hai hộp thoại này.
+ trong nút thống kê , chúng tôi nhấp vào hộp điều chỉnh mô hình để điều chỉnh mô hình, chúng tôi kiểm tra chẩn đoán tỷ lệ cột của đa cộng tuyến. trong vùng hệ số hồi quy , chúng tôi nhấp vào ước tính ước tính , khoảng tin cậy (thường được đặt thành 95%). trong vùng còn lại, chúng tôi chọn hộp durbin-watson về mức độ tương quan.
+ để sử dụng kiểm tra durbin-watson , phương trình hồi quy phải bao gồm một điểm chặn, vì vậy bao gồm hằng số trong phương trình phải được chọn trong các tùy chọn .
.button
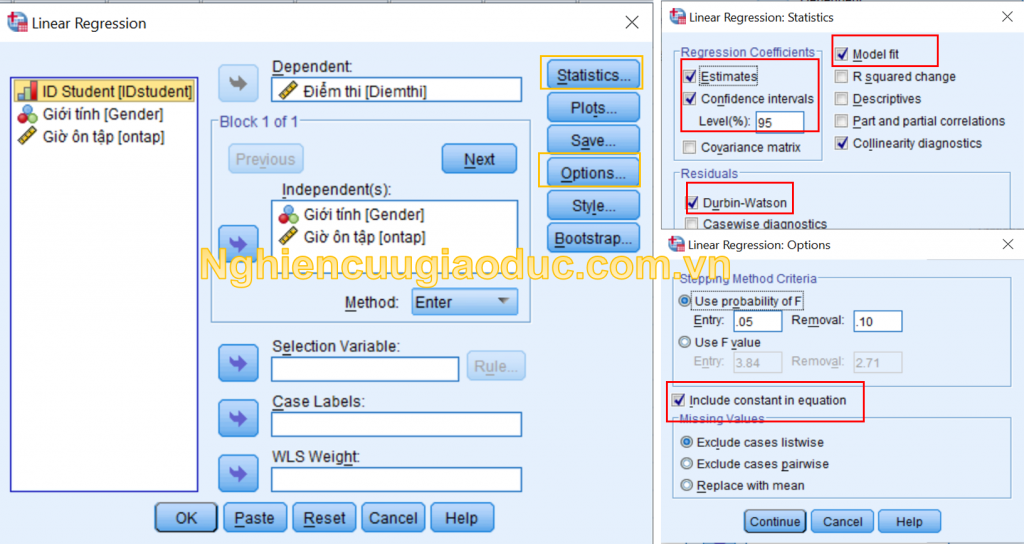
+ trong nút biểu đồ, phần dư của ước lượng được vẽ đồ thị dựa trên giá trị của biến hồi quy để xác minh hiện tượng phương sai của biến và phân phối chuẩn của phần dư. chúng tôi di chuyển mục nhập * zresid vào hộp y: , mục nhập * zpred vào hộp x: . sau đó nhấp vào hộp biểu đồ , biểu đồ xác suất thông thường .

+ sau mỗi bước cấu hình trên các nút, chúng tôi nhấp vào tiếp tục để hoàn tất.
– bước 4: nhấp vào ok để chạy kết quả phân tích hồi quy.
spss thống kê sẽ tạo ra khá nhiều bảng kết quả cho một hồi quy tuyến tính. bảng quan tâm đầu tiên là tóm tắt mô hình .
.

Bảng này cung cấp các giá trị của r và r2 (và r2 đã điều chỉnh), sai số của ước tính và giá trị d từ thử nghiệm durbin-watson. giá trị r đại diện cho mối tương quan và trong ví dụ r = 0,838, cho thấy mức độ tương quan cao. giá trị r2 (cột “r bình phương”) cho biết tỷ lệ phần trăm của tổng biến thể trong các biến phản hồi, diemthi, có thể được giải thích bằng các biến giải thích, ontap và giới tính. trong trường hợp này, 70,2% được giải thích, một con số rất cao. Ngoài ra, giá trị thống kê d của phép thử Durbin-Watson bằng 2,176 trong khoảng 1,5 đến 2,5, cho thấy không có tương quan nối tiếp bậc nhất (tự tương quan) giữa các chất thải. trong trường hợp d nhỏ hơn 1,5 biểu thị mối tương quan bậc một dương và d lớn hơn 2,5 biểu thị mối tương quan bậc một phủ định.
Bảng sau đây là bảng anova, báo cáo sự phù hợp của phương trình hồi quy với dữ liệu (tức là dự đoán của biến phản hồi).

Bảng này cho thấy rằng mô hình hồi quy dự đoán tốt biến phản hồi. Làm sao chúng ta biết được điều này? nhìn vào hàng “ hồi quy ” và chuyển đến cột “ tiếp theo ”. điều này cho thấy ý nghĩa thống kê của mô hình hồi quy đã được chạy. ở đây, p <0,05 và cho thấy rằng, nói chung, mô hình hồi quy dự đoán ý nghĩa thống kê trong các biến phản hồi (tức là nó phù hợp với dữ liệu).
Để xác nhận ý nghĩa thống kê đối với sự phù hợp của mô hình hồi quy tổng thể, giá trị f thu được (kiểm định f) được so sánh với giá trị f tới hạn, hãy xem bảng để biết giá trị tới hạn của phân phối f ( f-phân phối ). giá trị tới hạn của f trong bảng phân phối f được xác định bằng giao điểm giữa cột v1 (df của tử số của f) và hàng v2 (df của mẫu số hoặc sai số của f).
v1 = số tham số β trong mô hình hồi quy – 1 = 3-1 = 2
v2 = n – số tham số β trong mô hình hồi quy = 20 – 3 = 17
Tra cứu bảng phân phối f với mức ý nghĩa 5% trong cột 1 và hàng 18 để nhận giá trị f tới hạn là 3,59.
kết quả của bài kiểm tra f trong bảng anova là 20.022 & gt; 3.59 cho thấy mô hình hồi quy tổng quát có ý nghĩa thống kê, tức là các biến giải thích “giờ ôn tập” và “giới tính” là những yếu tố dự báo có ý nghĩa đối với biến phản hồi “điểm thi cuối kỳ”. toán học giải thích của học sinh. “
bảng hệ số cung cấp cho chúng tôi thông tin cần thiết để dự đoán ‘điểm kiểm tra’ từ ‘giới tính’ (x1) và ‘thời gian sửa đổi’ (x2), cũng như để xác định xem hai điều này các biến giải thích đóng góp đáng kể về mặt thống kê vào mô hình (quan sát cột “ sig. “). ngoài ra, chúng tôi có thể sử dụng các giá trị của cột “ b ” trong cột “ hệ số chuẩn hóa “.

trong bảng hệ số , các hệ số của phương trình hồi quy tuyến tính đơn bao gồm hằng số giới hạn là 42,5 và tham số β1 của ước tính tham số giới tính là 7942 và tham số β1 của ước lượng tham số giới tính là 7942. β2 của ước lượng tham số thời gian xem xét là 3235. Kết quả cho thấy cả hai hệ số đều có ý nghĩa thống kê (p <0,05). phương trình hồi quy là: diemthi = 42,5 + 7942 (giới tính) + 3235 (ontap) .
mỗi hệ số β cho biết mức tăng trung bình của điểm kiểm tra so với mức tăng 1 đơn vị của một yếu tố giải thích (biến giải thích). cụ thể điểm trung bình môn thi cuối kỳ của nam sinh cao hơn nữ 7.942 điểm (theo thang điểm 100). o Tăng 1 giờ ôn tập môn Toán đi kèm với việc tăng điểm thi cuối kỳ lên 3235 điểm (theo thang điểm 100).
khoảng tin cậy không bao gồm 0 và tất cả các giá trị đều dương, vì vậy, hợp lý khi kết luận rằng chúng tôi tin tưởng 95% vào việc tìm ra mối quan hệ thuận chiều giữa điểm thi cuối kỳ môn toán được giải thích với yếu tố giới tính và thời gian ôn tập của sinh viên. cụ thể, chúng tôi mong đợi điểm thi cuối kỳ môn toán giải thích sẽ tăng lên theo giờ ôn tập của mỗi học sinh, có thể nằm trong khoảng từ 1763 đến 4707 với mức tăng đơn vị trung bình là 3235, hoặc chúng tôi dự kiến điểm của bài kiểm tra cuối kỳ đối với nam, học sinh nam cao hơn trung bình 7.942 điểm so với học sinh nữ, có thể dao động từ 0,701 đến 15,183 điểm (khoảng rất rộng). điều này có thể là do cỡ mẫu nhỏ hoặc cần các nghiên cứu giải thích thêm.
trong cột thống kê tính tương đồng , cột yếu tố lạm phát phương sai vif (yếu tố lạm phát phương sai) & lt; 2 cho thấy đa cộng tuyến bị loại bỏ. (nếu hệ số lạm phát phương sai (vif)> 2 cho thấy dấu hiệu của đa cộng tuyến, điều này là không mong muốn. nếu vif> 10 thì chắc chắn là đa cộng tuyến). chúng ta cũng có thể thấy giá trị dung sai bằng cách sử dụng công thức dung sai = 1 / vif. hệ số này ở cột bên trái của hệ số vif. tương ứng: nếu hệ số dung sai nhỏ hơn 0,5 thì có dấu hiệu đa cộng tuyến, điều này không mong muốn. nếu dung sai nhỏ hơn 0,1 thì chắc chắn có đa cộng tuyến. tuy nhiên, đa cộng tuyến bị loại bỏ trong ví này do giá trị dung sai & gt; 0,5.
bảng
chẩn đoán tính cộng tuyến cung cấp số liệu thống kê liên quan đến tính đa cộng tuyến.

Bảng Thống kê phần dư cung cấp thống kê phần dư với các mô tả tối thiểu, tối đa, trung bình và độ lệch chuẩn. trong ví dụ cho thấy giá trị trung bình của các phần dư bằng không đáp ứng giả định của phân tích hồi quy.

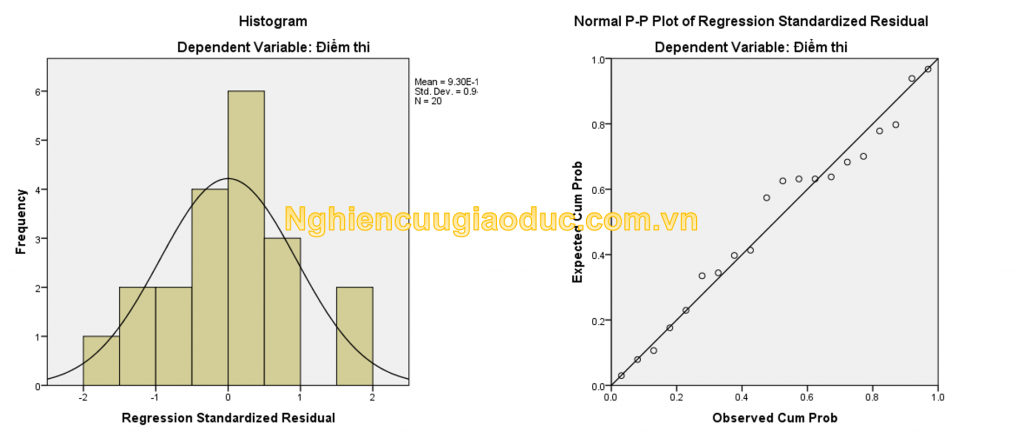
đồ thị phần dư chuẩn hóa hồi quy ( phần dư chuẩn hóa hồi quy ) của biến phản hồi và ‘điểm kiểm tra’ cho biết phân phối của phần còn lại. bạn có thể thấy một số thanh hơi cao và xuyên qua đường cong tiêu chuẩn. nhưng nhìn chung, mặc dù có một số sai lệch so với đường chuẩn, không nhiều. hầu hết các nhà phân tích sẽ kết luận rằng phần còn lại được phân phối xấp xỉ chuẩn (xấp xỉ chuẩn / xấp xỉ bình thường). trong đồ thị p-p bình thường của phần dư chuẩn hóa hồi quy (đồ thị p-p bình thường của phần dư chuẩn hóa hồi quy) của biến phản hồi và ‘điểm kiểm tra’ cho thấy rằng các giá trị quan sát được xấp xỉ phân phối đường thẳng tương ứng với phân phối bình thường. kết quả này cho thấy rằng các phần dư có phân phối xấp xỉ chuẩn.
trong biểu đồ phân tán các phần dư so với các giá trị phản hồi (tức là mối quan hệ giữa phần dư chuẩn hóa hồi quy và giá trị dự đoán được chuẩn hóa hồi quy ) thường được sử dụng để kiểm tra a) tính đồng nhất và b) các giả định về độ tuyến tính. nếu cả hai giả định đều đúng, biểu đồ phân tán này sẽ không hiển thị bất kỳ đường mẫu nào.
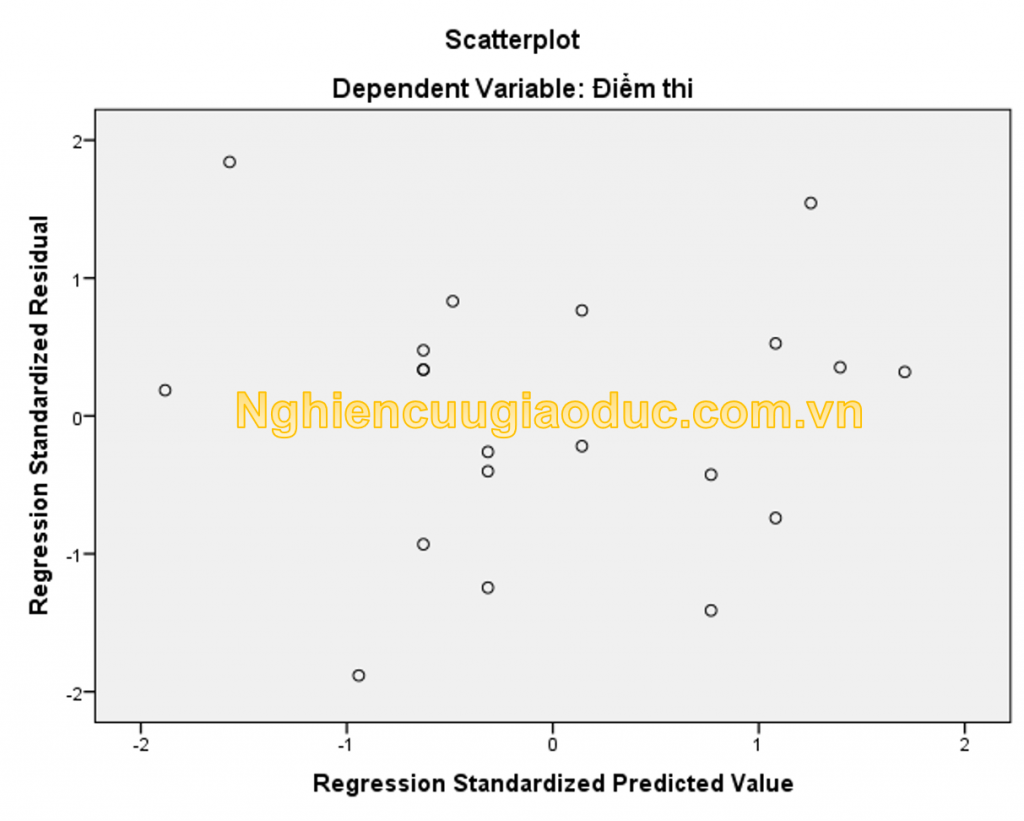
: Kiểm tra phổ biến cho giả định tuyến tính là kiểm tra xem các điểm trên biểu đồ phân tán này có hiển thị một số loại đường cong hay không. đó không phải là trường hợp ở đây, vì vậy tuyến tính dường như cũng được chấp nhận ở đây.
: Phương sai của các phần dư là đồng nhất vì chúng tôi ước tính cách xa nhau của các điểm theo chiều dọc trên biểu đồ phân tán của chúng tôi. vì vậy chiều cao của biểu đồ phân tán của chúng tôi không được tăng hoặc giảm khi chúng tôi di chuyển từ trái sang phải.
tài liệu tham khảo
- coolicano, h. (2018). Phương pháp nghiên cứu và thống kê trong tâm lý học. routledge.
- hanneman, r. a., kposowa, a. j., & amp; bí ẩn, m. d. (2012). thống kê cơ bản cho nghiên cứu xã hội (quyển 38). John Wiley & amp; con trai.
- jackson, s. tôi (2015). Phương pháp nghiên cứu và thống kê: Phương pháp tiếp cận tư duy phản biện. học tập liên tục.
- mcqueen, r. a., & amp; knussen, c. (Năm 2006). Giới thiệu về phương pháp nghiên cứu và thống kê trong tâm lý học. giáo dục pearson.
- nghiên cứu sinh, tôi. (Năm 2006). Phân tích thống kê cho các nhà nghiên cứu trong giáo dục và tâm lý học: công cụ cho các nhà nghiên cứu trong giáo dục và tâm lý học. routledge.
- wagner iii, w. tôi. (2019). Sử dụng Thống kê SPSS® của IBM cho các Phương pháp Nghiên cứu và Thống kê Khoa học Xã hội. bài đăng của hiền triết.
Như vậy trên đây chúng tôi đã giới thiệu đến bạn đọc Bài 3. Phân tích hồi quy tuyến tính bội (Multiple Linear Regression). Hy vọng bài viết này giúp ích cho bạn trong cuộc sống cũng như trong học tập thường ngày. Chúng tôi xin tạm dừng bài viết này tại đây.
Website: https://phebinhvanhoc.com.vn/
Thông báo: Phê Bình Văn Học ngoài phục vụ bạn đọc ở Việt Nam chúng tôi còn có kênh tiếng anh PhebinhvanhocEN cho bạn đọc trên toàn thế giới, mời thính giả đón xem.
Chúng tôi Xin cám ơn!
![TOP 5 TỪ ĐIỂN ONLINE KHÔNG THỂ THIẾU CHO NGƯỜI CHƠI HỆ ANH – ANH] | Anh ngữ AMES](https://phebinhvanhoc.com.vn/wp-content/uploads/dictionary-nghia-la-gi.png "TOP 5 TỪ ĐIỂN ONLINE KHÔNG THỂ THIẾU CHO NGƯỜI CHƠI HỆ ANH – ANH] | Anh ngữ AMES")


![[Fine Art là gì?] Lựa chọn nghề phù hợp nhất cho tín đồ nghệ thuật](https://phebinhvanhoc.com.vn/wp-content/uploads/fine-arts-la-gi.jpg "[Fine Art là gì?] Lựa chọn nghề phù hợp nhất cho tín đồ nghệ thuật")

